

The humble Microsoft Excel file can wreak havoc in large scale eDiscovery. One lesser known cause for concern is its pivot table cache, which can deceive reviewers, potentially resulting in the disclosure of privileged or confidential data.
TL;DR (too long; didn’t read)
- Excel workbooks cache data that may be referenced in other workbooks
- Not all processing engines extract this information
- The impact of this can be significant on document review where privileged and confidential information is inadvertently disclosed or not captured for review
Impending doom
The doom that often accompanies the presence of Microsoft Excel files in document review, is something many eDiscovery professionals can empathise with. Excel files are complex beasts with an underlying data structure to match. This particular piece discusses one part of this underlying structure – the pivot cache – which has the ability to circumvent traditional searching methods if not appropriately handled.
Hidden in plain sight
Spreadsheets contain several layers of data, many of which contribute to the way information is presented back to end users.
If you are using a Windows file system, a quick way to visualise this is to change the extension of any Microsoft Excel workbook to ‘.zip’:

The result is a zip bundle that contains the following folder structure:
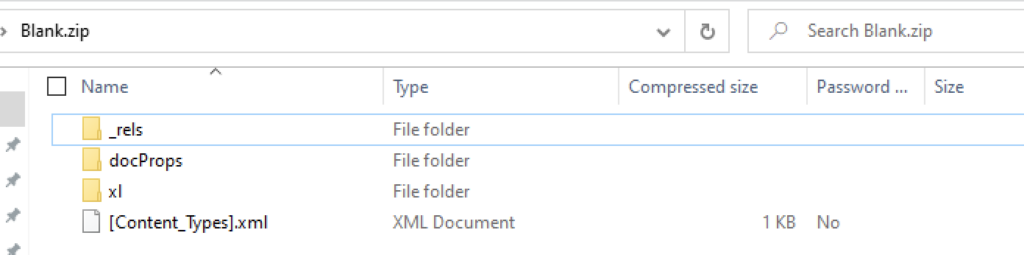
These folders represent the underlying structure of your workbook which is broadly broken down in the following ways:
- FOLDER – _rels – stores the package relationships required for the operation of the workbook
- FOLDER – docProps – file level metadata, ie: written by/written on
- FOLDER – xl – contains the actual content in your workbook
- FILE – [Content_types].xml – contains references to the XML files within the folders above
Digging Deeper
Let’s take this further. Consider two workbooks and their underlying folder structure:
- Example one – a blank workbook
- Example two – a workbook that also contains a table, some formatting and a pivot table
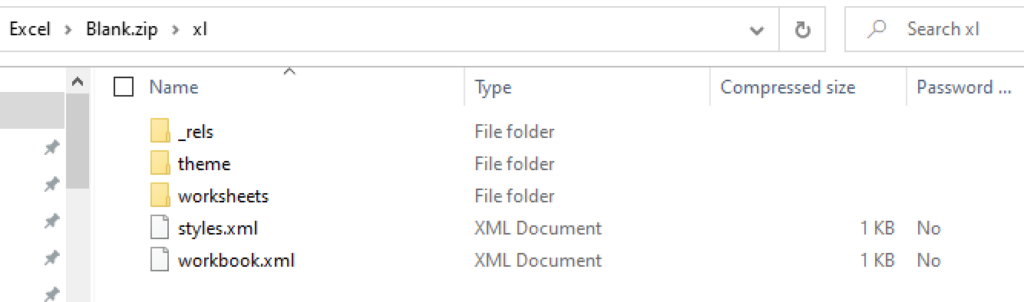
Taking a look into the ‘xl\’ location of both these examples allows us to observe how particular features impact the underlying Excel data structure:
Example one – the blank excel workbook contains the default ‘xl\’ structure
Example two – the addition of a table, pivot table, content and formatting adds extra material to the ‘xl\’ location:
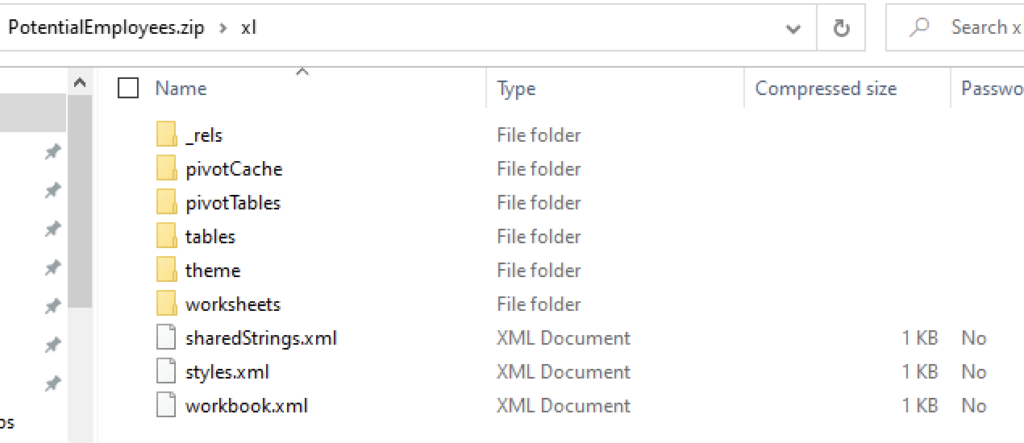
It’s clear that as the workbook becomes more complex so too does the underlying structure.
Introducing the pivotCache
In example two (above) – the presence of the folder titled ‘pivotCache’ uncovers an interesting challenge for budding eDiscovery enthusiasts.
When a pivot table is generated in Microsoft Excel, a cache is created that stores the underlying data. This cache, is a replica of the pivot data source and acts as the location that the workbook references when conducting calculations. It is stored in the ‘xl\pivotCache’ location and explains why pivot tables are able to generate and regenerate themselves so quickly, irrespective of their source volume. It also accounts for the ballooning file size that often accompanies workbooks with pivot tables:

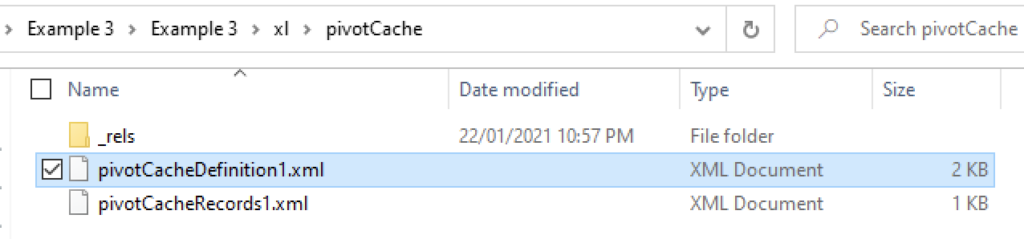
By opening the pivotCacheDefinition1.xml we see an XML representation of the pivot data source:
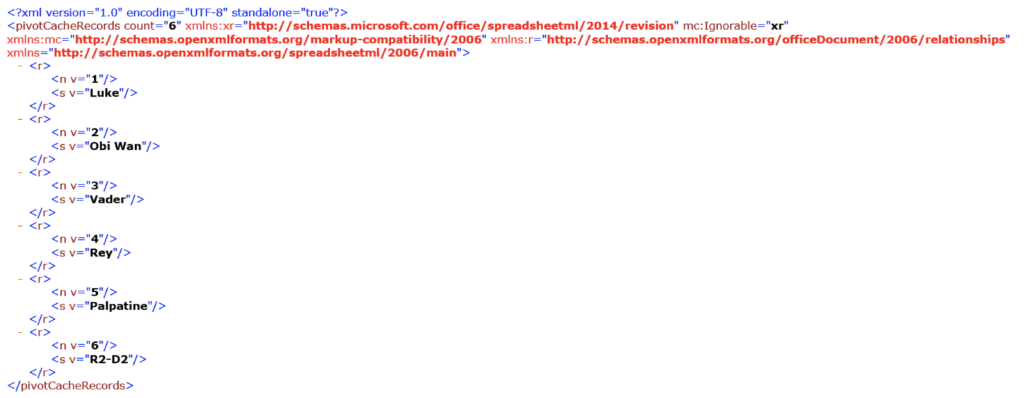
More commonly viewed as any table or range in a workbook:

There are some things about the above that are interesting. One, all data in Excel is stored in a readily accessible XML format. And two, this data is just duplication other XML files not contained in the pivotCache folder. As such, the pivotCache here only contains only information visible on the face of the document – which isn’t remarkable in the slightest!
But let’s take this a little further. Let’s consider how you might go about creating a pivot table:
- there’s the traditional method where you point to data somewhere in your workbook;
- there’s the slightly more advanced method of creating that pivot from a named range or table – or;
- there’s the out of this world method of pointing to a datasource not in your current file.
It’s the last of the three options above where the pivot table cache begins to cause problems.
The dark side of the force
As has probably become clear by now, an Excel workbook creates a replica of the data source that powers a pivot table and stores it within its file structure. The examples we have dealt with so far provide instances where the replicated data does not contain unique information – because it is drawn from within the workbook. However, as we are about to see, this replication also extends to data being referenced from external workbooks. That is, data that isn’t immediately apparent on the face of the document.
Example three (below) is a spreadsheet that contains a blank pivot table. That pivot table was generated over a table range from an external workbook. As you can see, the generated pivot table remains blank.
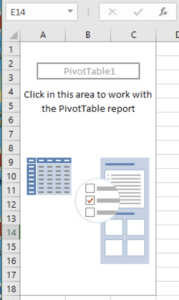
On the face of the document, there is no data to review. And unlike the examples referred to above (see example two), there is no source data stored on any other sheet in the workbook. However, if we take a look at the underlying pivotCache, we notice that there is indeed source data sitting in the cache.
Which contains:

This data, as you may have guessed, is the associated pivot source in the external workbook!
The mechanics of what is going on here presents significant issues in document review:
- First, if a processing engine does not unpack the pivotCache, the data that sits beneath the pivot table is not searchable. And if a document’s content is not fully searchable, applying keywords will ultimately produce a flawed result.
- Second, without visibility of this content, spreadsheets that are responsive by virtual of family relationships (or other responsive content) may not be appropriately considered for privilege or confidentiality prior to production.
- And third, without visibility of content within the pivotCache, parties become unaware of the extent to which they are disclosing material to their counterparts – and whether their counterparts are able to extract the material.
Thus, significant burden is placed on the capability of eDiscovery tools to handle the information stored within the pivot cache.
To extract or not to extract
The answer to whether the material contained within the pivotCache should be extracted, is, well, complicated.
The nature of the pivot cache is such that it presents itself as an XML file that is part of the Excel structure. The data contained within the pivotCache can easily be retrieved if a document reviewer was to fully expand the corresponding pivot table. On the other hand, it is rare for the role of a reviewer to go beyond interrogating a document on face value. Where a pivot table is concerned, the existing combination of fields selected and arranged in a particular way could very well be material – or relied upon in other areas of the workbook. As such, altering the workbook to access the underlying cache could have a profound effect on the nature of a document.
It seems that eDiscovery processing engines too are at odds with how to treat the pivotCache.
Testing conducted on engines including Nuix Workstation, EDT and Relativity show that all three engines negate to unpack the pivotCache – or indeed the underlying Excel file structure. Text extracted by each of these engines only contained material visible on the face of the document, which then naturally feeds into respective search indexes. Further, none of these tools remove the cache from the native version of spreadsheet that ultimately gets exported.
One processing tool that did manage to extract the underlying pivotCache was Access Data’s FTK.
A special mention must also be given to Nuix Discover. Although it performed inconsistently when compared with its processing counterpart -Nuix Workstation – it managed to extract the underlying cache when indexing and enrichment was run over the sample Excel file.
It would be valuable to understand from the wider community what your experience is using other tools to unpack Excel files with pivot tables?
The unknown known
From professionals I’ve spoken to in industry, it is clear that the pivotCache is not something widely known about.
Without trying to quote former United States Secretary of Defence, Donald Rumsfeld, these professionals and their understanding of the pivotCache can be summarised in three ways:
- The known known – professionals who are aware of its existence, unpack the information and take it into account during review
- The known unknown – professionals who are aware of its existence but have no way to mass extract the information to make it accessible in review
- The unknown unknown – professionals unaware of its existence and do not take it into account during review
For those who fall into either ‘known’ bucket, there’s a lot to be discussed about handling a pivotCache in review. Of particular interest:
- How do you go about presenting this information to reviewers in context?
- How do you flag the existence of this content?
- Where do you begin if you need to apply redactions directly to the pivotCache
There’s also an interesting discussion to be had about the relevance of material stored in the pivot cache. Rendering down (potentially via pasting) the values stored in the pivot negates the existence of the cache without impacting the information shown by the pivot table. In some ways, it is similar to handling formulas that can no longer be evaluated because of a changed environment – but even that situation doesn’t present obvious solution.
Altering the caching behaviour
Microsoft gives users the ability to alter the caching behaviour of pivot tables in spreadsheets. The effect of this is that the pivotCache folder does not store the externally referenced information in the same way.
Let’s look again at example three from earlier and observe what happens when we disable the cache. Unlike the pivot in example three, I’ve selected a field to demonstrate how the pivot table behaves when these new options are applied.
Disabling the cache is as easy as altering pivot table options and selecting the following choices:
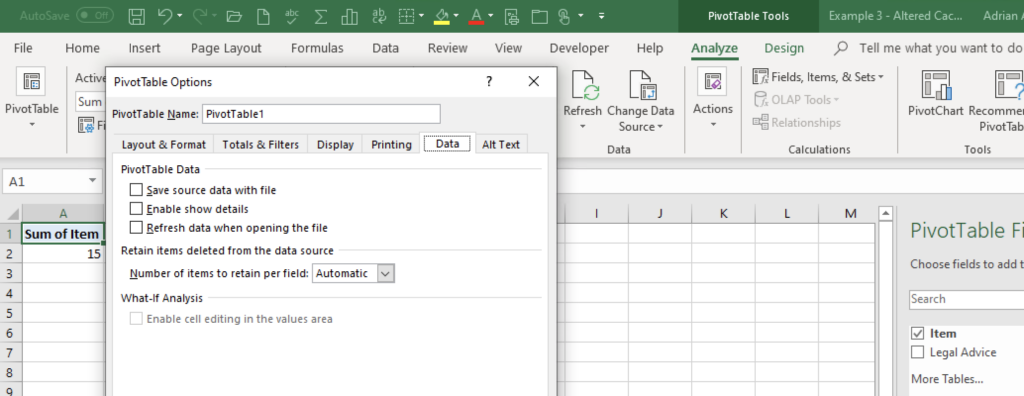
Saving down the workbook with these options applied, we then observe the following change in the underlying file structure:

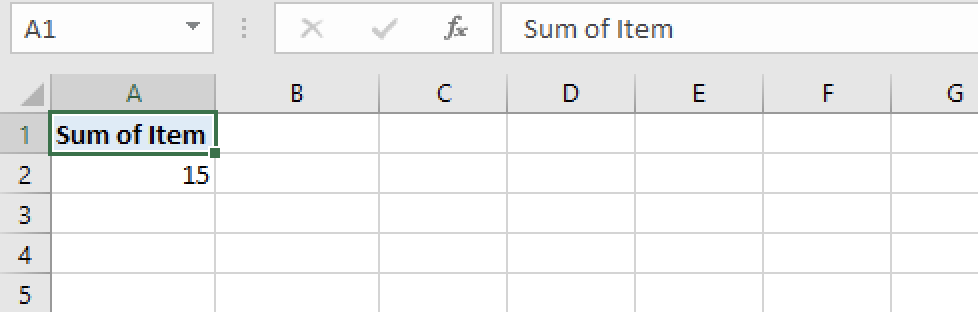
Opening up the workbook, we notice that the choices selected in the pivot table remain:
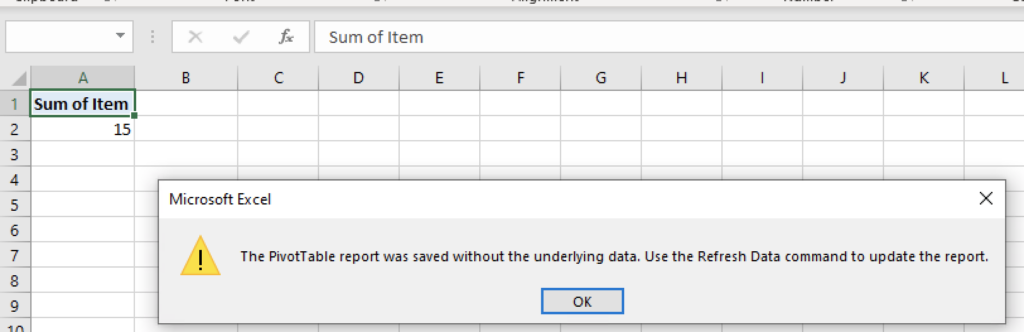
If we try to alter the pivot table, we get notified that the source data is no longer available, preventing us from accessing the information:
This is the perfect scenario for discoverable material as it preserves document content in its original format – without disclosing additional information.
Unfortunately, disabling the pivotCache needs to be done on a document by document basis – which is impractical on large scales and in existing evidence repositories. An option exists to write a macro using the PivotCache.WorkbookConnection to bulk apply these settings to multiple workbooks – but again, this requires a workflow outside of your eDiscovery platform.
Moving forward
As data volumes grow, Microsoft Excel files will naturally grow in complexity. This, coupled with additional promised functionality, such as LAMBDA functions and increased O365 integration, will only increase the importance of handling workbooks correctly in the eDiscovery process.
In my view, it is something that needs to be addressed by processing and redacting tools alike, sooner rather than later.


Fascinating and somewhat scary
Thank you for detailed explanation 🙂